Reading a vLLM Startup Log: A Field Guide to LLM Inference Concepts
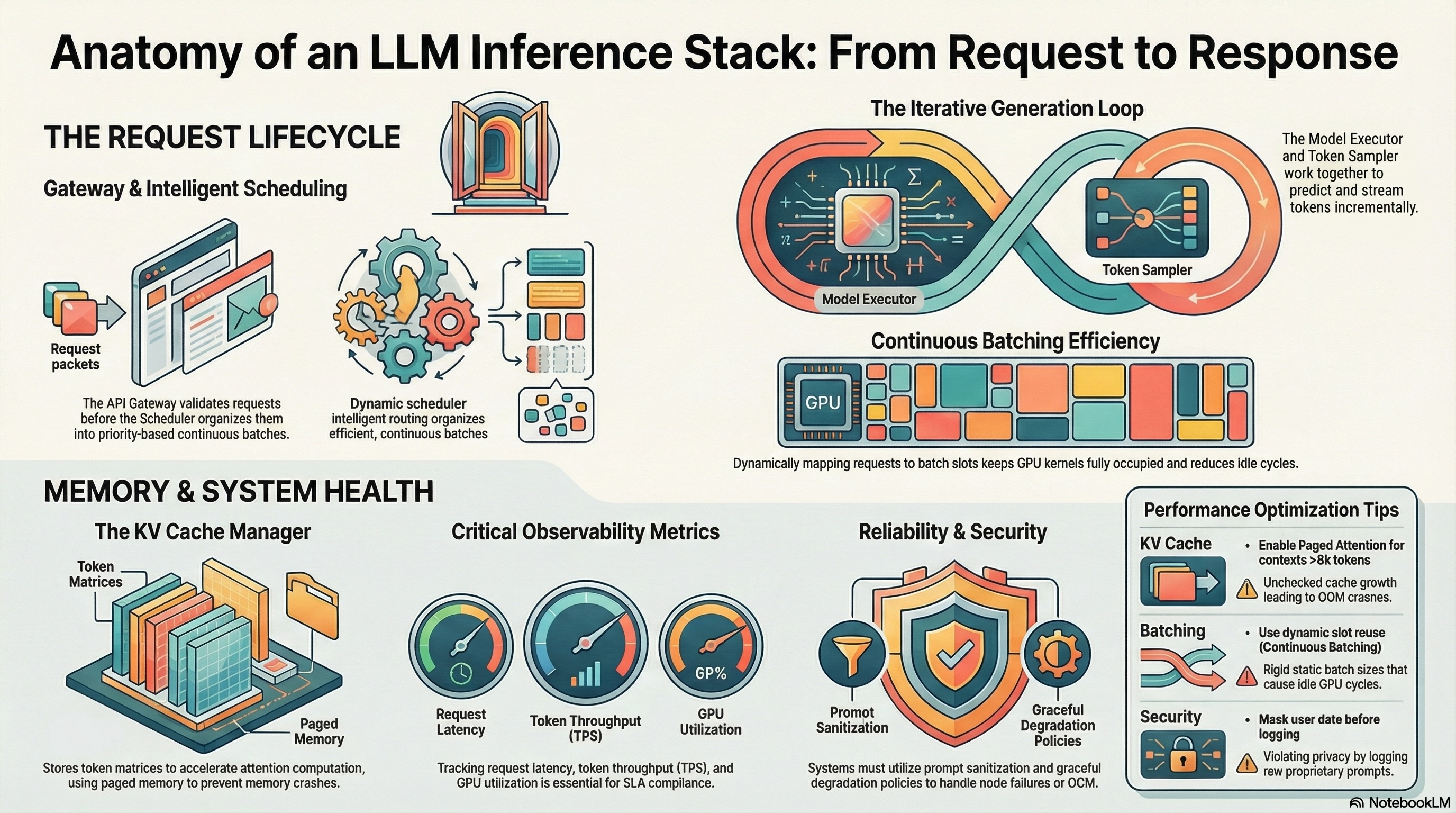
To make that concrete, I took a real cold-start log from a vLLM deployment of Gemma 4 (31B, NVFP4) on an H100 and annotated it line by line. Every interesting line is tagged, grouped into phases, and explained—what the number means, why it's there, and which knob it maps back to. This post is the conceptual companion: it walks through the same startup sequence as a way to understand the dimensions of inference and the concepts attached to each one.
The annotated log
This post explains the concepts. The annotated log shows them in the wild—30 tagged entries across 7 startup phases, filterable by category, with the raw output inline.
Open the annotated vLLM startup log →Why a startup log is a good teacher
A forward pass is hard to observe—it's milliseconds of GPU kernels. But startup is slow and verbose, and it forces the engine to commit to numbers: how many tokens fit in cache, how much VRAM the weights take, how much is left over. Those commitments are exactly the trade-offs that govern inference. Read in order, the log tells a story in seven phases.
Phase by phase: the dimensions of inference
01 Process startup & model identification
02 Quantization, KV cache format & attention backend
03 Model download & weight loading
04 FP8 scaling & encoder cache
05 torch.compile & Inductor
06 CUDA graph capture & KV cache sizing
07 API server startup & route registration
The concepts worth internalizing
If you take away nothing else, these are the levers the log keeps pointing at:
- Context window vs. KV cache. The window is the per-request ceiling; the cache is the shared budget. Concurrency is the cache divided by how much each active sequence consumes.
- Precision is a capacity decision. FP8/FP4 aren't just "smaller"—they change how many tokens and users fit on a card, with correctness caveats around scaling factors.
- Compilation is amortized, not free. The cold-start cost buys faster steady-state kernels and is cached for warm restarts.
- CUDA graphs trade startup time for decode throughput, and quietly reshape what --gpu-memory-utilization delivers.
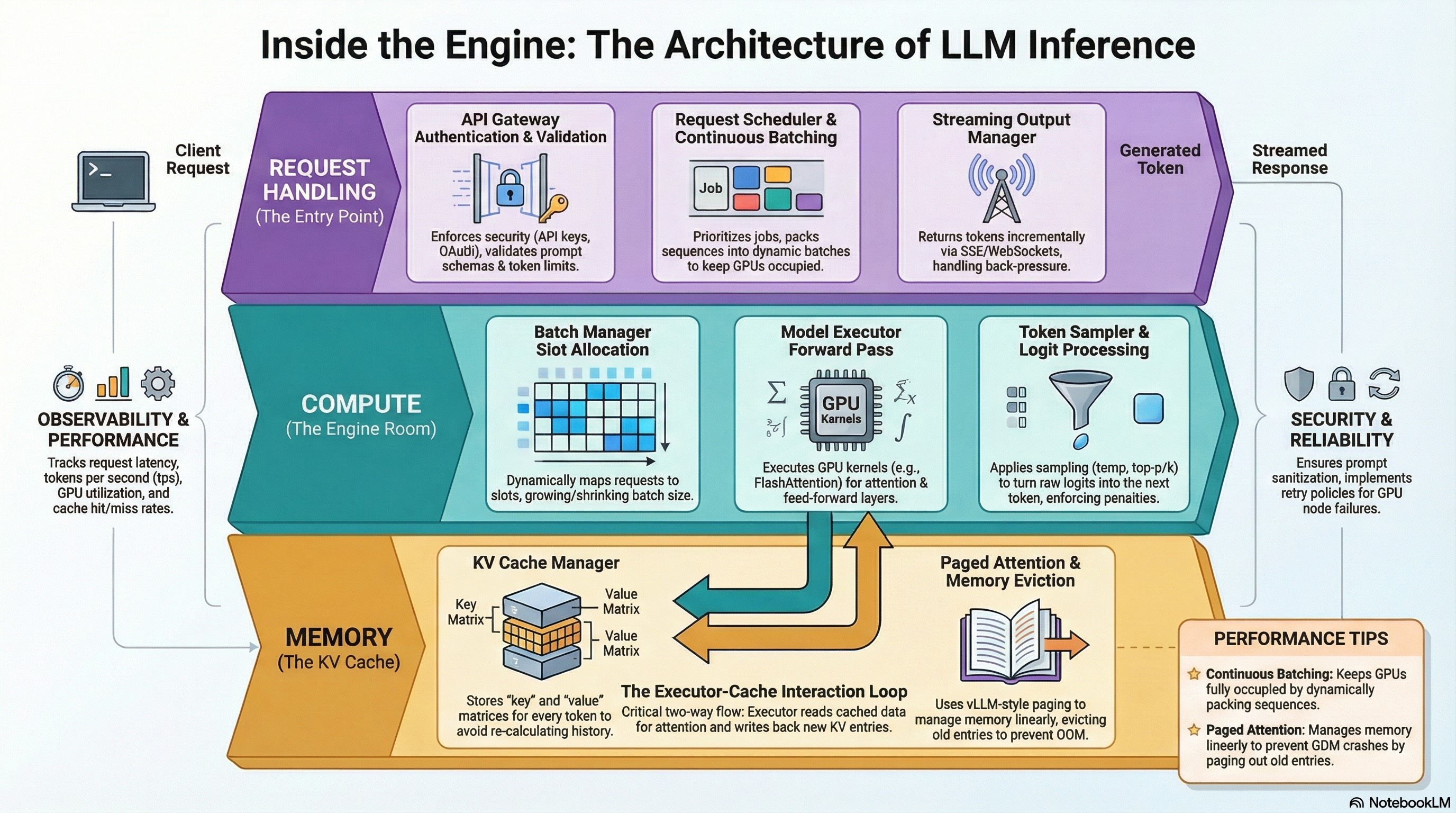
Ready to see these phases in the raw output? The annotated reference has the full log, filterable by key decisions, warnings, architecture, memory, and compilation.
Read the annotated vLLM startup log →References
- vLLM. vLLM — GitHub repository.
- vLLM Startup Log — Annotated Reference (Gemma-4-31B-IT-NVFP4).